平成27年春期試験午後問題 問3

問3 データベース
自治会員の情報を管理する関係データベースの設計及び運用に関する次の記述を読んで,設問1~4に答えよ。
X地区の自治会では,世帯数の増加と,個人情報管理の厳格化を背景に,手書きの帳票で管理していた自治会員の情報を電子化することにした。この自治会には,236世帯,667人が登録されていて,各世帯は1~8班のいずれかに所属している。
従来は図1に示すとおり,世帯ごとに,世帯主氏名,住所,電話番号,登録日,所属する班,同居者氏名,続柄,性別,生年月日などの情報を管理していた。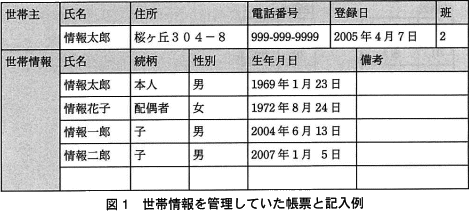 図1の帳票を基に,図2に示す表構成をもつ関係データベースを作成した。下線付きの項目は,主キーを表す。
図1の帳票を基に,図2に示す表構成をもつ関係データベースを作成した。下線付きの項目は,主キーを表す。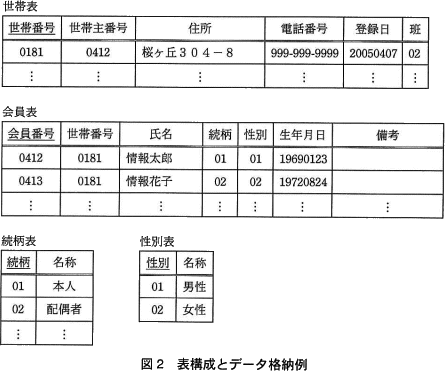 〔表の説明〕
〔表の説明〕
X地区の自治会では,世帯数の増加と,個人情報管理の厳格化を背景に,手書きの帳票で管理していた自治会員の情報を電子化することにした。この自治会には,236世帯,667人が登録されていて,各世帯は1~8班のいずれかに所属している。
従来は図1に示すとおり,世帯ごとに,世帯主氏名,住所,電話番号,登録日,所属する班,同居者氏名,続柄,性別,生年月日などの情報を管理していた。
- 世帯表の世帯番号には,各世帯に一意に割り当てた番号が格納されている。
- 世帯表の世帯主番号には,世帯主の会員番号が格納されている。
- 会員表の会員番号には,各会員に一意に割り当てた番号が格納されている。
- 会員表の世帯番号には,会員が属する世帯の世帯番号が格納されている。
広告
設問1
図2の表構成を完成するまでの設計について,次の記述中の に入れる適切な答えを,解答群の中から選べ。
図1の帳票は非正規形なので,まず,a世帯情報を取り出して会員表を作成した。次に,b続柄表と性別表を作成した。続柄表と性別表のレコード件数は少ないが,例えば,帳票の記載で"男"と"男性"のように同じ意味を表すデータに対する定義の一意性を保証できる効果がある。
図1の帳票は非正規形なので,まず,a世帯情報を取り出して会員表を作成した。次に,b続柄表と性別表を作成した。続柄表と性別表のレコード件数は少ないが,例えば,帳票の記載で"男"と"男性"のように同じ意味を表すデータに対する定義の一意性を保証できる効果がある。
a,b に関する解答群
- 障害回復のために
- 第1正規化に基づいて
- 第2正規化に基づいて
- 第3正規化に基づいて
- 排他制御のために
解答選択欄
- a:
- b:
- a=イ
- b=エ
解説
関係データベースの正規化は次のように3段階に分けて行います。- 第1正規化
- 繰り返し項目をなくし、主キーを設定する
- 第2正規化
- 主キーの一部によって一意に決まる項目を別表に移す
- 第3正規化
- 主キー以外の項目によって一意に決まる項目を別表に移す。
図1の世帯情報が記入された帳票をそのままレコードにすると以下のように繰り返し項目を含むものになります。

会員表は、帳票の繰り返し項目である世帯情報をそれぞれ1つのレコードとして定義することで作成された表です。
a=イ:第1正規化に基づいて
〔bについて〕
第1正規化が終わった後に行うのは第2,第3正規化です。
まず第2正規化ですが世帯表と会員表の主キーは単一の属性値であり、部分関数従属が存在しないためこの時点で第2正規形の条件を満たしています。
続く第3正規化では主キー以外の項目同士の関数従属性に注目します。会員表の"続柄"で続柄名称が、"性別"によって性別の称が一意に決定されるので、この2つの関係が会員表から別表へ分離されています。
したがって続柄表と性別表の作成は、第3正規化に基づいて行われたことになります。
∴b=エ:第3正規化に基づいて
広告
設問2
地区の福祉委員会から,1940年よりも前に生まれた会員が含まれる世帯の世帯番号について,情報提供を求められた。該当する世帯番号を抽出する正しいSQL文を解答群の中から選べ。
なお,同じ世帯番号は一つだけ抽出する。
なお,同じ世帯番号は一つだけ抽出する。
解答群
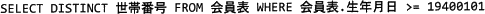
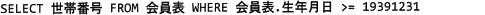
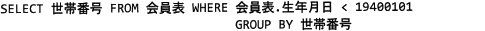
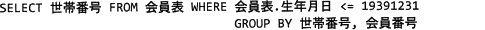
解答選択欄
- ウ
解説
- 生年月日の比較条件 ">= 19400101" は生年月日が1940年以後のレコードが抽出されてしまうので不適切です。
- 生年月日の比較条件 ">= 19391231" は生年月日が1939年12月31日以後のレコードが抽出されてしまうので不適切です。
- 正しい。生年月日の比較条件 "< 19400101" で1940年よりも前に生まれた会員行を抽出し、世帯番号ごとにグループ化することで重複のない世帯番号を抽出します。
- 生年月日の比較条件は適切です。しかしグループ化の列として2つの列を指定していることが原因で、1つの世帯に2人以上の対象者がいる以下のような場合に抽出される世帯番号が重複してしまうため不適切です。
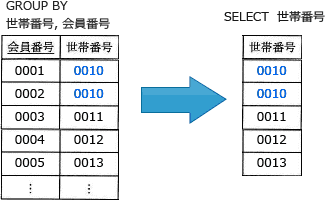
広告
設問3
班ごとの会員数に偏りがあるとの意見が挙がったので,班の再編を検討することになった。現在の状況を確認するために,班ごとの世帯数と会員数を集計する。次のSQL文の に入れる正しい答えを,解答群の中から選べ。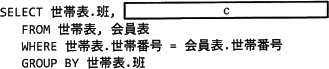
c に関する解答群
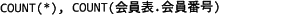
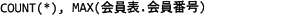
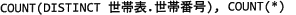
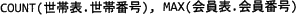
解答選択欄
- c:
- c=ウ
解説
設問のSQL文では世帯表と会員表を結合して、班ごとにグループ化しています。この処理によってできる表は、自治会に所属する会員すべてが、班ごとにグループ化されたものになります。COUNT(*)はグループ内のレコード数を取得する集計関数なので、上記のグループ化された表に対してCOUNT(*)を指定することで班ごとの会員数を表示することができます。
また班ごとの世帯数は、班ごとにグループされた中に何種類の世帯番号が存在するかを調べればよいので、COUNT(世帯表.世帯番号)にDISTINCTを指定し、COUNT(DISTINCT 世帯表.世帯番号)とすることで重複行をカウントしないようにします。
したがって正しい組合せは「ウ」です。
- 自治会に所属する全ての会員には会員番号が割り当てられているため COUNT(会員表.会員番号) はCOUNT(*)と同じ値になります。
- MAX(会員表.会員番号)は、班員に割り当てられている番号のうち最も値の大きい番号が取得されるだけなので不適切です。
- 正しい。
- COUNT(世帯表.世帯番号)では1つの世帯に2名以上の会員が所属する場合に重複してカウントされてしまうため不適切です。
広告
設問4
地区の子供会役員から,子供会に所属する子供の情報を照会できるようにしてほしいとの要望が挙がったので,図3に示すビューを作成することにした。子供会には,生年月日が 20030402~20090401 の会員が所属する。次のSQL文の に入れる正しい答えを,解答群の中から選べ。
d に関する解答群
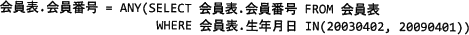
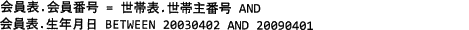

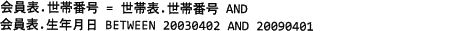
解答選択欄
- d:
- d=エ
解説
まず子供会表には会員表にはない"電話番号"列があるので会員表と世帯表を結合する必要があることがわかります。この時点で表の結合を指定していない「ア」「ウ」は条件を満たしません。会員表の"世帯番号"を世帯表の"世帯番号"と関連付けたいので、表の結合条件は「会員表.世帯番号 = 世帯表.世帯番号」が適切です。
次に子供会に所属する会員を生年月日を基準として抽出する操作ですが、ある列の値が一定の範囲内にあるレコードを抽出したい場合にはBETWEEN句を使用します。
BETWEEN句の構文は、
列名 BETWEEN 最小値 AND 最大値
となっているため、生年月日が 20030402~20090401 である会員を抽出する指定は、 生年月日 BETWEEN 20030402 AND 20090401
が適切です。したがって「エ」が適切です。
広告
広告