平成31年春期試験午後問題 問3

問3 データベース
定期健康診断のデータが登録されているデータベースに関する次の記述を読んで,設問1~3に答えよ。
D中学校では,年に1回,定期健康診断を実施し,結果をデータベースに登録している。
身長と体重の測定結果は,身長の単位はcm,体重の単位はkgとして,いずれも0.1刻みで健診結果表に登録している。定期健康診断を受ける生徒の生年月日,性別などの属性情報は,受診者情報表に登録している。
健診結果表を作成するSQL文の一部と,受診者情報表を作成するSQL文を次に示す。 ここで,DECIMAL(x,y)は固定小数点数を扱うデータ型であり,xは精度であって,表示する数字の桁数を示し,yは位取りであって,小数点以下の数字の桁数を示す。例えば,データベースに175.5を登録するには,xに4を,yに1を指定する。
ここで,DECIMAL(x,y)は固定小数点数を扱うデータ型であり,xは精度であって,表示する数字の桁数を示し,yは位取りであって,小数点以下の数字の桁数を示す。例えば,データベースに175.5を登録するには,xに4を,yに1を指定する。
健診結果表及び受診者情報表のデータ(以下,定期健康診断データという)から,身長と体重を統計データとして参照するために,測定結果ビューを使用する。測定結果ビューを作成するSQL文を次に示す。
D中学校では,年に1回,定期健康診断を実施し,結果をデータベースに登録している。
身長と体重の測定結果は,身長の単位はcm,体重の単位はkgとして,いずれも0.1刻みで健診結果表に登録している。定期健康診断を受ける生徒の生年月日,性別などの属性情報は,受診者情報表に登録している。
健診結果表を作成するSQL文の一部と,受診者情報表を作成するSQL文を次に示す。
健診結果表及び受診者情報表のデータ(以下,定期健康診断データという)から,身長と体重を統計データとして参照するために,測定結果ビューを使用する。測定結果ビューを作成するSQL文を次に示す。
広告
設問1
2010年度から2019年度までの定期健康診断データを基に,男子生徒の体格の推移を見る。次のSQL文の実行結果を用いて,図1に示す体格推移表を作成した。平均身長と平均体重は小数第2位を四捨五入した値である。SQL文の に入れる正しい答えを,解答群の中から選べ。ここで,c1とc2に入れる答えは,cに関する解答群の中から組合せとして正しいものを選ぶものとする。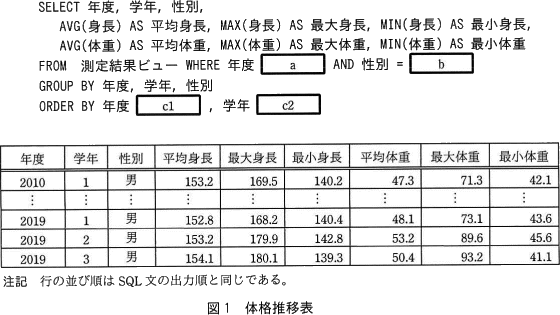
a に関する解答群
- LIKE '201_'
- LIKE '2010'
- LIKE '2019'
- = '201%'
- = '201_'
- = '201*'
b に関する解答群
- 0
- 1
- '男'
- '女'
- '-'
c に関する解答群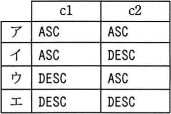
解答選択欄
- a:
- b:
- c:
- a=ア
- b=ウ
- c=ア
解説
〔aについて〕集計対象となる年度は2010年度から2019年度までですので、これに対応する字句が入ります。本来であれば範囲検索を行うBETWEEN句を使う※ところなのですが、年度のデータ型が"CHAR(4)"ということもあり、文字列としての一致を条件に行を選択する条件式になっています。
LIKE句は、指定したパターンと文字列比較を行うための演算子で、次の特殊記号を用いて文字列のパターンを指定します。
- _ … 任意の1文字
- % … 0文字以上の任意の文字列
- 正しい。
- 年度が2010の行のみが選択されます。
- 年度が2019の行のみが選択されます。
- ワイルドカードを使用した文字列は、LIKE句と同時に使用しなければ効果を生じません。年度が"201%"の行は存在しませんので結果は0行になります。
- 「エ」と同じく、"="で比較すると単に同じ文字列の行だけが選択されます。年度が"201_"の行は存在しませんので結果は0行になります。
- 年度が"201*"の行は存在しませんので結果は0行になります。"*"は正規表現において0文字以上を表す文字ですが、LIKE句では使用しません。
※BETWEEN句は、数値型や日付型の範囲検索をするための式ですが、多くのDBMSでは文字型であっても比較可能です。文字列としての比較の場合、ソートしたときの登場順で前後が決まるため可変長の文字列では検索が上手くいきませんが、本問の"年度"列は4文字の固定長であるため問題なく処理されます。
〔bについて〕
集計対象は男子生徒のみであるため、性別の値を用いて男子生徒のみを選択するための字句が入ります。設問1のSQL文の対象となっている"測定結果ビュー"の定義文を見ると、性別の値はCASE句を用いて以下のように定義されています。
CASE 受信者情報表.性別
WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '-'
END
SQLのSELECT文内でCASE句を使用すると、プログラムのif~else構造のように列の値が条件式に合致するかどうかによって返す値を変えることができます。上記の場合、0の場合には"男"、1の場合には"女"、どちらでもない場合には"-"が返されるということです。受信者情報表では性別情報が整数値(SMALLINT型)で管理されていますが、測定結果ビューでは性別を示す文字列になるということです。WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '-'
END
設問1のSQL文では、測定結果ビューのうち男子生徒の行のみを選択したいのですから、「性別 = '男'」という条件式が適切となります。
∴b=ウ:'男'
〔cについて〕
ORDER BY句の列名に続けて記述する"ASC"と"DESC"は、どちらも整列の向きを指定する字句です。
- ASC … 昇順(値の小さい順)に整列(デフォルト値)
- DESC … 降順(値の大きい順)に整列
∴c=ア
広告
設問2
次の記述中の に入れる正しい答えを,解答群の中から選べ。
D中学校では,転入生を受け入れる場合,転出元の中学校から受領した定期健康診断の結果の情報をデータベースに登録する。健診結果表には,受診者IDと年度にd制約を設定し,受診者IDに受診者情報表の受診者IDへのe制約を設定している。この制約に従うと,転入生の定期健康診断の結果の情報の健診結果表への登録は,受診者情報表に転入生の情報を登録した後に行う必要がある。
D中学校では,転入生を受け入れる場合,転出元の中学校から受領した定期健康診断の結果の情報をデータベースに登録する。健診結果表には,受診者IDと年度にd制約を設定し,受診者IDに受診者情報表の受診者IDへのe制約を設定している。この制約に従うと,転入生の定期健康診断の結果の情報の健診結果表への登録は,受診者情報表に転入生の情報を登録した後に行う必要がある。
d,e に関する解答群
- UNIQUE
- 検査
- 参照
- 主キー
- 非NULL
解答選択欄
- d:
- e:
- d=エ
- e=ウ
解説
〔dについて〕受信者IDと年度に注目して健診結果表を定義するCREATE TABLE文を見ると、以下の記述があります。
PRIMARY KEY(年度, 受信者ID)
PRIMARY KEYは、指定した列に主キー制約を課す文です。平たく言えば主キーを指定する文です。主キー制約が課された列(または列の組合せ)は、NULL値が許されず、表の中で一意の値を持つことが強制されます。よってdには「主キー」が入ります。
∴d=エ:主キー
〔eについて〕
先程と同じ受診者IDに注目すると以下の記述があります。
FOREIGN KEY(受診者ID)
REFERRENCE 受診者情報表(受診者ID)
FOREIGN KEYは、外部キーを指定する文です。外部キーを指定する際には、REFERRENCEで参照先の列を指定します。REFERRENCE 受診者情報表(受診者ID)
外部キーを設定された列は、参照先の列に存在しない値を設定できなくなります。また参照先の列は、外部の表から参照されている値がある場合、その値を含む行を更新したり削除したりできなくなります。この表間の整合性を保つための2つの制約を合わせて参照制約といいます。
よってeには「参照」が入ります。
∴e=ウ:参照
広告
設問3
次の記述中の に入れる正しい答えを,解答群の中から選べ。
図2に示す身長階級表を作成し,これに対応させて,2019年度の男子生徒の定期健康診断データを基に,図3に示す身長度数分布表を作成したところ,"人数が相違している"との指摘があった。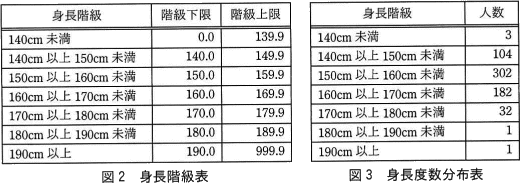 図3に示す身長度数分布表の作成は,次の(1)~(3)の手順で行った。
図3に示す身長度数分布表の作成は,次の(1)~(3)の手順で行った。 図1を見ると,2019年度は男子全学年での最大身長が180.1cmであり,190cm以上の生徒は存在しないが,図3の身長度数分布表では,190cm以上の人数が1となっている。この原因は,(2)で作成したSQL文ではfとすべき箇所をCOUNT(*)としていることにある。その結果,測定結果ビューと身長階級表を結合した結果において,NULLとなっているレコードもカウントしているからである。
図1を見ると,2019年度は男子全学年での最大身長が180.1cmであり,190cm以上の生徒は存在しないが,図3の身長度数分布表では,190cm以上の人数が1となっている。この原因は,(2)で作成したSQL文ではfとすべき箇所をCOUNT(*)としていることにある。その結果,測定結果ビューと身長階級表を結合した結果において,NULLとなっているレコードもカウントしているからである。
図2に示す身長階級表を作成し,これに対応させて,2019年度の男子生徒の定期健康診断データを基に,図3に示す身長度数分布表を作成したところ,"人数が相違している"との指摘があった。
- 図2に示す身長階級表をデータベースに作成した。
- 新たなSQL文を作成した。
- (2)で作成したSQL文の実行結果を用いて,図3に示す身長度数分布表を作成した。
f に関する解答群
- COUNT(身長)
- COUNT(身長階級)
- MAX(身長)
- MAX(身長階級)
- 身長
- 身長階級
解答選択欄
- f:
- f=ア
解説
設問3のSQL文で使用されている"RIGHT OUTER JOIN"は、右外部結合を指定する句です。右外部結合とは、基準となる右表の行を全て抽出し、左表からは右表の行と結合できる行のみを抽出する結合方法です。対応する左表の行が存在しない場合にはNULLで埋められます。設問のSQL文を実行した場合、グループ化及び整列が済んだ時点で上位3階級の状態は次のようになっています。
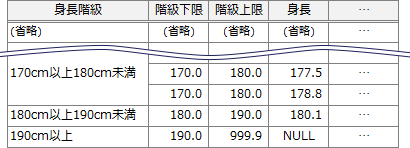
- 正しい。
- "身長階級"列を対象にカウントすると身長がNULLの行を除外できません。
- 人数ではなく、階級ごとの最大身長が表示されます。
- "身長階級"列には、身長の範囲を示す文字列が格納されているだけなので、その最大値を集計することに意味はありません。
- GROUP BY句で指定していない"身長"列は、SELECT文の列に指定できないので構文エラーになります。
- 単に"身長階級"列の値が表示されるだけなので誤りです。
広告
広告