平成24年秋期試験午後問題 問3

問3 ネットワーク
電子メールで用いるMIME形式に関する次の記述を読んで,設問1,2に答えよ。
インターネットの電子メールは,規格上,US-ASCIIのような 7 ビット符号で書かれたテキストしか送信できない。そのため,UTF-8のような 8 ビット符号で書かれたテキストや,画像データなどのバイナリデータを電子メールで送信する際は,MIME(Multipurpose Internet Mail Extensions)と呼ばれる書式(以下,MIME形式という)に従ってメッセージを作成する。
MIME形式では,7 ビット符号で書かれたテキスト以外のコンテンツを,base64 や quoted-printable などの方式で 7 ビット符号に変換(以下,エンコードという)する。ただし,エンコードを行うコンピュータのメモリ上では,7 ビット符号を,先頭に0のビットを1ビット付加した8ビット(1バイト)として取り扱う。
base64 によるエンコードでは,コンテンツを先頭から 6 ビットごとに区切り,各 6 ビットを,ビットパターンごとに定められた,US-ASCIIの図形文字 1 文字に変換する。
一方,quoted-printable によるエンコードでは,コンテンツをバイト列とみなし,US-ASCIIの制御文字又は図形文字"="と一致するバイト,及び先頭ビットが 1 のバイトを,"=XX"(XXは2桁の16進数字列)の形の3文字のUS-ASCIIの図形文字列に置き換える。US-ASCIIの図形文字("="を除く)と一致するバイトは置き換えない。幾つかの例外があるが,ここでは考慮しなくてよいものとする。
例えば,UTF-8で書かれたテキスト"©△IPA△2012."("©"には16進数で C2A9 の 2 バイトの符号が,他の文字にはUS-ASCIIと同じ 1 バイトの符号が,それぞれ割り当てられている)をa1でエンコードすると"=C2=A9△IPA△2012."になる。同じテキストをa2でエンコードすると"wqkgSVBBIDIwMTIu"となり,いずれもUS-ASCIIに含まれる図形文字だけから成る 7 ビット符号のバイト列となる。ここで,"△"は空白(符号は16進数で20)を表すものとする。
エンコード後のデータ量に着目すると,大部分がUS-ASCIIに含まれる図形文字で構成されているテキストのエンコードにはa3が適しており,バイナリデータのエンコードにはa4が適している。
UTF-8では,平仮名1文字に先頭ビットが1であるバイト三つから成る符号を割り当てているので,UTF-8で書かれた 6 文字の平仮名から成るテキストを quoted-printable でエンコードすると,b文字の文字列となる。
インターネットの電子メールは,規格上,US-ASCIIのような 7 ビット符号で書かれたテキストしか送信できない。そのため,UTF-8のような 8 ビット符号で書かれたテキストや,画像データなどのバイナリデータを電子メールで送信する際は,MIME(Multipurpose Internet Mail Extensions)と呼ばれる書式(以下,MIME形式という)に従ってメッセージを作成する。
MIME形式では,7 ビット符号で書かれたテキスト以外のコンテンツを,base64 や quoted-printable などの方式で 7 ビット符号に変換(以下,エンコードという)する。ただし,エンコードを行うコンピュータのメモリ上では,7 ビット符号を,先頭に0のビットを1ビット付加した8ビット(1バイト)として取り扱う。
base64 によるエンコードでは,コンテンツを先頭から 6 ビットごとに区切り,各 6 ビットを,ビットパターンごとに定められた,US-ASCIIの図形文字 1 文字に変換する。
一方,quoted-printable によるエンコードでは,コンテンツをバイト列とみなし,US-ASCIIの制御文字又は図形文字"="と一致するバイト,及び先頭ビットが 1 のバイトを,"=XX"(XXは2桁の16進数字列)の形の3文字のUS-ASCIIの図形文字列に置き換える。US-ASCIIの図形文字("="を除く)と一致するバイトは置き換えない。幾つかの例外があるが,ここでは考慮しなくてよいものとする。
例えば,UTF-8で書かれたテキスト"©△IPA△2012."("©"には16進数で C2A9 の 2 バイトの符号が,他の文字にはUS-ASCIIと同じ 1 バイトの符号が,それぞれ割り当てられている)をa1でエンコードすると"=C2=A9△IPA△2012."になる。同じテキストをa2でエンコードすると"wqkgSVBBIDIwMTIu"となり,いずれもUS-ASCIIに含まれる図形文字だけから成る 7 ビット符号のバイト列となる。ここで,"△"は空白(符号は16進数で20)を表すものとする。
エンコード後のデータ量に着目すると,大部分がUS-ASCIIに含まれる図形文字で構成されているテキストのエンコードにはa3が適しており,バイナリデータのエンコードにはa4が適している。
UTF-8では,平仮名1文字に先頭ビットが1であるバイト三つから成る符号を割り当てているので,UTF-8で書かれた 6 文字の平仮名から成るテキストを quoted-printable でエンコードすると,b文字の文字列となる。
広告
設問1
記述中の に入れる正しい答えを,解答群の中から選べ。ただし,a1~ a4に入れる答えは,a に関する解答群の中から組合せとして正しいものを選ぶものとする。
a に関する解答群
b に関する解答群
- 8
- 18
- 24
- 54
解答選択欄
- a:
- b:
- a=エ
- b=エ
解説
〔aについて〕"©△IPA△2012."をa1でエンコードすると"=C2=A9△IPA△2012."になります。元のテキストのうちUTF-8である"©"だけが置き換えされ他の部分は置き換えされていないことから、US-ASCIIの図形文字は置き換えをしない「quoted-printable」とわかります。
a1が「quoted-printable」なので、a2は「base64」です。
次に考えるのはエンコード後のデータ量です。
前述の通り「quoted-printable」ではUS-ASCII図形文字の変換を行わないので、大部分がUS-ASCIIのテキストであればエンコードに伴う余分なデータの付加はわずかな量となるので「quoted-printable」が有利となります。
バイナリデータのエンコードですが、「base64」では6ビットごとに1文字に置き換えされます。8ビットの3文字が6ビットの4つのブロックに区切られ4文字に置き換えされるため、エンコード後のデータ量は元のデータの4/3倍になります。
一方「quoted-printable」では、先頭ビットが1のバイトとUS-ASCIIの制御文字、及び"="がそれぞれ"=XX"という3文字に置き換えられます。バイナリデータでは先頭ビットが1のバイトと0のバイトの出現確率がほぼ同じと考えることができるので、エンコード後のおよそのデータ量は、
1×1/2+3×1/2=2(倍)
上記の計算からビットが一様に分布するバイナリデータでは「base64」方式の方がエンコード後のデータ量を少ないことがわかります。
したがってa3=quoted-printable,a4=base64 が適切です。
∴a=エ
〔bについて〕
平仮名1文字は3バイトで構成されています。それぞれのバイトは先頭ビットが1なので、そのバイトを16進表記2文字の形式にして、その前に"="を付加した3文字"=XX"にエンコードされます。
したがって平仮名1文字は(3×3=)9文字、6文字の平仮名では(9×6=)54文字にエンコードされます。
b=エ:54
広告
設問2
MIME形式を使用すると,1通の電子メールに複数のコンテンツを格納することができる。1通の電子メールに二つのコンテンツを格納したMIME形式のメッセージは,図1のようになる。 boundary="delimiter" の delimiter には,格納したコンテンツの区切りを示す文字列を指定する。
boundary="delimiter" の delimiter には,格納したコンテンツの区切りを示す文字列を指定する。
delimiter の先頭に"--"を付けたものが1つのコンテンツの開始を示し,delimiter を"--"で囲ったものが最後のコンテンツの終了を示す。
delimiter には,コンテンツに含まれる行が,誤ってコンテンツの区切りと認識されることのないような文字列を,選択しなければならない。
"コンテンツごとの属性を示すヘッダー"には,テキストや画像などのコンテンツの種類や,エンコードの方式などを指定する。エンコードの方式には"base64"や"quoted-printable"のほか,コンテンツがエンコードされていない7ビット符号のテキストであることを示す"7bit"などが指定できる。
図1中の"コンテンツ1"が7ビット符号のテキストであって,図2に示す3行をコンテンツに含むとき,delimiter としてふさわしくない文字列を,解答群の中から三つ選べ。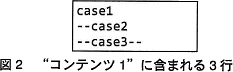
delimiter の先頭に"--"を付けたものが1つのコンテンツの開始を示し,delimiter を"--"で囲ったものが最後のコンテンツの終了を示す。
delimiter には,コンテンツに含まれる行が,誤ってコンテンツの区切りと認識されることのないような文字列を,選択しなければならない。
"コンテンツごとの属性を示すヘッダー"には,テキストや画像などのコンテンツの種類や,エンコードの方式などを指定する。エンコードの方式には"base64"や"quoted-printable"のほか,コンテンツがエンコードされていない7ビット符号のテキストであることを示す"7bit"などが指定できる。
図1中の"コンテンツ1"が7ビット符号のテキストであって,図2に示す3行をコンテンツに含むとき,delimiter としてふさわしくない文字列を,解答群の中から三つ選べ。
解答群
- --case1
- --case2
- --case3
- case1
- case2
- case3
- case1--
- case2--
- case3--
解答選択欄
- オ
- カ
- ケ
解説
delimiterとしてふさわしくない文字列とは、コンテンツの先頭及びコンテンツの最後として用いたときに、"コンテンツ1"の内容の一部が誤ってdelimiterとして判定されてしまうものです。解答群の全ての文字列でコンテンツの先頭及びコンテンツの最後を表現したものと、"コンテンツ1"の内容を比較すると以下のようになります。
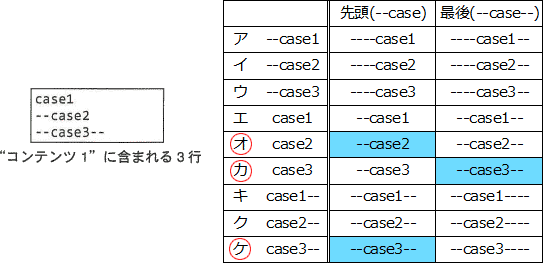
∴オ,カ,ケ
広告
広告