平成30年秋期試験問題 午前問4

問4解説へ
出現頻度の異なるA,B,C,D,Eの5文字で構成される通信データを,ハフマン符号化を使って圧縮するために,符号表を作成した。aに入る符号として,適切なものはどれか。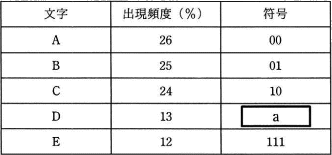
- 001
- 010
- 101
- 110
広告
解説
ハフマン符号化は、可変長の符号化方式で、出現確率が高いデータには短い符号を、低いデータには長い符号を与えることで圧縮を効率よく行う方法です。
ハフマン符号では、符号化のビット列に全く同じ符号の並びが存在しないように、ある文字に対応する符号が、他の文字に対応する符号の接頭辞にならないように設定されます。これにより単純に先頭から読んでいくだけでデコードができます。
ハフマン符号では、符号化のビット列に全く同じ符号の並びが存在しないように、ある文字に対応する符号が、他の文字に対応する符号の接頭辞にならないように設定されます。これにより単純に先頭から読んでいくだけでデコードができます。
010000111101011000101110111001
↓
01 00 00 111 10 10 110 00 10 111 01 110 01
↓
BAAECCDACEBDB
設問の表を見ると"00"、"01"、"10"、"111"は既に割当て済なので、Dにはこれ以外のビット列から開始する符号を与える必要があります。↓
01 00 00 111 10 10 110 00 10 111 01 110 01
↓
BAAECCDACEBDB
- Aの符号"00"が接頭辞になっています。デコードの際に先頭部分がAに変換されてしまうため不適切です。
- Bの符号"01"が接頭辞になっています。デコードの際に先頭部分がBに変換されてしまうため不適切です。
- Cの符号"10"が接頭辞になっています。デコードの際に先頭部分がCに変換されてしまうため不適切です。
- 正しい。既存のどの符号からも始まっていないため適切です。
広告