
HOME»基本情報技術者平成25年秋期問題»午後問8
基本情報技術者過去問題 平成25年秋期 午後問8
⇄問題文と設問を画面2分割で開く⇱問題PDF問8 データ構造及びアルゴリズム
次のプログラムの説明及びプログラムを読んで,設問1,2に答えよ。
〔プログラムの説明〕
英字A~Zから構成される文字列を圧縮する副プログラム Compress,及び圧縮された文字列を復元する副プログラム Decompressである。
〔圧縮処理の説明〕
副プログラム Compress では,配列 Plaindata に格納されている圧縮前の文字列を受け取り,圧縮後の文字列を配列 Compresseddata に格納する。図1に示す文字列"ABCDEFABCDABCDEF"を例として,圧縮処理の内容を説明する。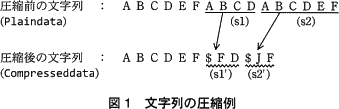
Compress の引数の仕様は,次のとおりである。各配列の添字は,0から始まる。 〔復元処理の説明〕
〔復元処理の説明〕
副プログラム Decompress では,配列 Compresseddata に格納されている圧縮された文字列を受け取り,復元後の文字列を配列 Plaindata に格納する。復元処理の内容を次に示す。
Decompress の引数の仕様は,次のとおりである。各配列の添字は,0から始まる。 副プログラム Compress と Decompress で使用している関数 IntToAlphabet と AlphabetToInt の仕様は,次のとおりである。
副プログラム Compress と Decompress で使用している関数 IntToAlphabet と AlphabetToInt の仕様は,次のとおりである。
〔関数 IntToAlphabet の仕様〕
整数 1~26 を順に英字 A~Z に変換する。IntToAlphabet の引数と返却値の仕様は,次のとおりである。 〔関数 AlphabetToInt の仕様〕
〔関数 AlphabetToInt の仕様〕
英字 A~Z を順に整数 1~26 に変換する。AlphabetToInt の引数と返却値の仕様は,次のとおりである。
〔プログラムの説明〕
英字A~Zから構成される文字列を圧縮する副プログラム Compress,及び圧縮された文字列を復元する副プログラム Decompressである。
〔圧縮処理の説明〕
副プログラム Compress では,配列 Plaindata に格納されている圧縮前の文字列を受け取り,圧縮後の文字列を配列 Compresseddata に格納する。図1に示す文字列"ABCDEFABCDABCDEF"を例として,圧縮処理の内容を説明する。
- 図1の圧縮前の文字列"ABCDEFABCD…"のように,"ABCD"という同じ文字の並びが複数回出現する場合,二つ目以降の"ABCD"を圧縮列に置き換えることによって,文字列の長さを短くする。図1では,Plaindata に格納されている圧縮前の文字並び(s1),(s2)を圧縮列(s1'),(s2')に置き換えて Compresseddata に格納している。
- 圧縮列は,制御記号,距離,文字数の三つの部分から成る。
- 制御記号は,"$"であり,圧縮列の先頭を表す。
- 距離と文字数は,圧縮前の文字列において,"この場所の文字並びは,何文字前(距離)の文字から始まる何文字の長さ(文字数)の文字並びと同じである"という内容を意味する。距離と文字数の最大値は 26 とし,1,2,…,26 を A,B,…,Z で表す。図1の例では,圧縮前の文字並び(s1)は,(s1)の先頭文字の 6 文字前から始まる長さ 4 の文字並び"ABCD"と一致するので,圧縮列(s1')は"$FD"となる。また,圧縮前の文字並び(s2)は,(s2)の先頭文字の 10 文字前から始まる長さ 6 の文字並び"ABCDEF"と一致するので,圧縮列(s2')は"$JF"となる。
- 圧縮処理は,配列 Plaindata に格納されている圧縮前の文字列中で,圧縮する文字並びを検索する検索処理と,検出した文字並びを圧縮列に置き換えて配列 Compresseddata に格納する置換処理から成る。
- 圧縮する文字並びの検索処理の内容を次に示す。
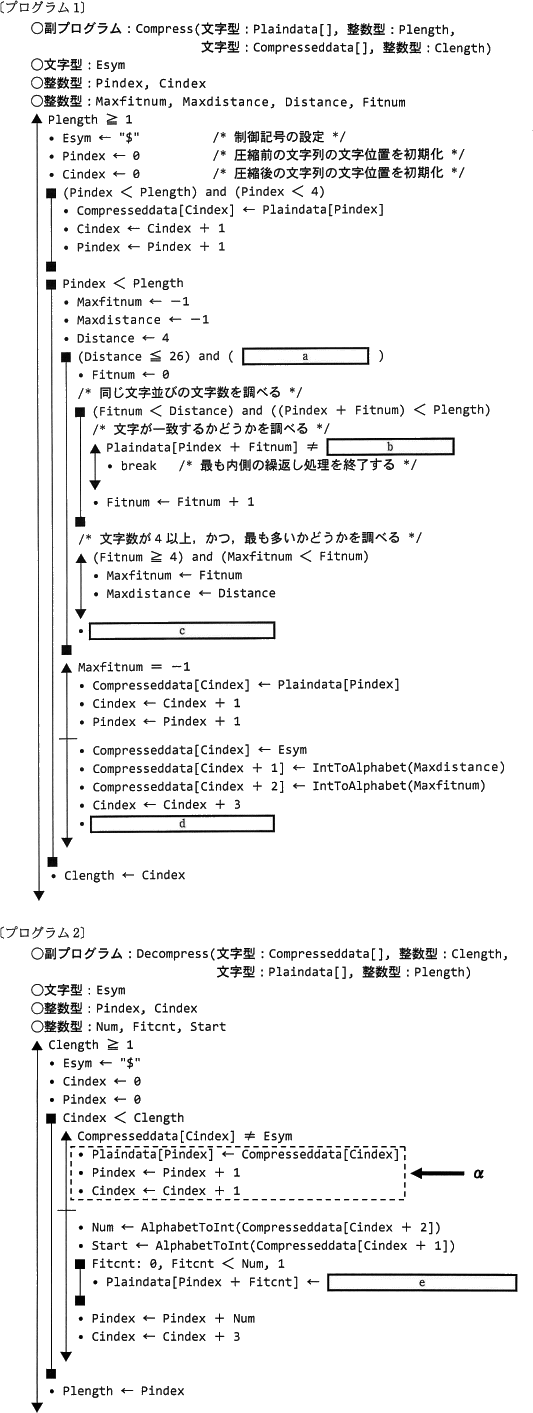
- 圧縮処理の対象となる文字並びを圧縮文字並び,圧縮文字並びの先頭位置を圧縮文字位置という。圧縮列の文字数は 3 なので,一致する文字数が 4 以上の圧縮文字並びの場合に圧縮列に置き換える。したがって,最初の圧縮文字位置は,図2に示すように圧縮前の文字列の先頭から 5 文字目となる。この文字位置から圧縮文字位置を文字列の後方に向かって移動させながら検索処理②,③を行う。
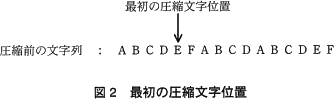
- 圧縮文字並びの比較対象とする文字並びを比較文字並び,比較文字並びの先頭位置を比較文字位置という。最初の比較文字位置は,図3に示すように圧縮文字位置の 4 文字前とする。
- 比較文字位置を文字列の先頭に向かって,圧縮文字位置から最大 26 文字前まで移動させながら,次の(a),(b)を行う。
- 圧縮文字位置と比較文字位置から文字列の後方に向かって,圧縮文字並びと比較文字並びが何文字一致するかを調べる。
図4は,圧縮文字位置が 7 文字目のときに,比較文字位置を文字列の先頭に向かって p1,p2,p3 と移動しながら,一致する文字を検索している様子を示している。比較文字位置 p1 と,p2 では,1文字目が一致していない。比較文字位置 p3 では1文字目が一致し,一致する文字数は 4 となる。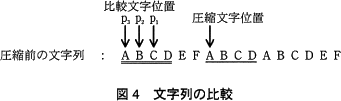
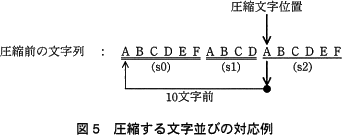
- 圧縮する文字並びは,それよりも前にある比較文字並びの中で,一致する文字数が 4 以上で最も多い比較文字並びとする。圧縮する文字並びの対応例を図5に示す。図5では,圧縮文字位置から始まる圧縮文字並び"ABCD…"と,それよりも前方に出現する比較文字並びの中で,一致する文字数が4以上の比較文字並びは,4文字前の(s1)"ABCD"と10文字前の(s0)"ABCDEF"である。したがって,一致する文字数が多い(s0)に対応させて,(s2)"ABCDEF"を圧縮列に置き換えることになる。
- 圧縮文字位置と比較文字位置から文字列の後方に向かって,圧縮文字並びと比較文字並びが何文字一致するかを調べる。
- 圧縮処理の対象となる文字並びを圧縮文字並び,圧縮文字並びの先頭位置を圧縮文字位置という。圧縮列の文字数は 3 なので,一致する文字数が 4 以上の圧縮文字並びの場合に圧縮列に置き換える。したがって,最初の圧縮文字位置は,図2に示すように圧縮前の文字列の先頭から 5 文字目となる。この文字位置から圧縮文字位置を文字列の後方に向かって移動させながら検索処理②,③を行う。
- (4)の検索処理の結果に対する置換処理の内容を次に示す。
- 一致する文字数が3以下の場合には,圧縮列に置き換えないで,圧縮文字位置の文字を配列 Compresseddata に格納する。
- 一致する文字数が4以上の場合には,その文字数が最も多い比較文字並びに対応する圧縮列を配列 Compresseddata に格納する。
Compress の引数の仕様は,次のとおりである。各配列の添字は,0から始まる。
副プログラム Decompress では,配列 Compresseddata に格納されている圧縮された文字列を受け取り,復元後の文字列を配列 Plaindata に格納する。復元処理の内容を次に示す。
- 配列 Compresseddata の先頭から圧縮された文字列を順に調べる。
- 文字が制御記号でなければ,その文字をそのまま配列 Plaindata に格納する。
- 文字が制御記号ならば,圧縮列の距離,文字数から,圧縮前の文字並びを復元して配列 Plaindata に格納する。
Decompress の引数の仕様は,次のとおりである。各配列の添字は,0から始まる。
〔関数 IntToAlphabet の仕様〕
整数 1~26 を順に英字 A~Z に変換する。IntToAlphabet の引数と返却値の仕様は,次のとおりである。
英字 A~Z を順に整数 1~26 に変換する。AlphabetToInt の引数と返却値の仕様は,次のとおりである。
設問1
プログラム中の に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
- Pindex - Distance ≧ 0
- Pindex - Plength ≧ 0
- Plength - Distance ≧ 0
- Plength - Pindex ≧ 0
b に関する解答群
- Plaindata[Pindex + Distance]
- Plaindata[Pindex + Distance + Fitnum]
- Plaindata[Pindex - Distance]
- Plaindata[Pindex - Distance + Fitnum]
c に関する解答群
- Cindex ← Cindex + 1
- Distance ← Distance + 1
- Fitnum ← Fitnum + 1
- Pindex ← Pindex + 1
- Plength ← Plength + 1
d に関する解答群
- Pindex ← Pindex + 1
- Pindex ← Pindex + 3
- Pindex ← Pindex + Maxdistance
- Pindex ← Pindex + Maxfitnum
e に関する解答群
- Compresseddata[Pindex + Start + Fitcnt]
- Compresseddata[Pindex - Start + Fitcnt]
- Plaindata[Pindex + Start + Fitcnt]
- Plaindata[Pindex - Start + Fitcnt]
解答選択欄
- a:
- b:
- c:
- d:
- e:
解答
- a=ア
- b=エ
- c=イ
- d=エ
- e=エ
解説
〔aについて〕
空欄にはループの継続条件が入ります。このループ処理は、変数 Distance が26以下であることを1つの継続条件としていること、および直前処理で②の記述にあるように Distance の初期値を4にしていることから、問題文(4)③で説明されている
「比較文字位置を文字列の先頭に向かって,圧縮文字位置から最大26文字前まで移動させながら,次の(a),(b)を行う」
に該当することがわかります。
この処理では、「圧縮文字位置と比較文字位置から文字列の後方に向かって,圧縮文字並びと比較文字並びが何文字一致するかを調べる」ことを、圧縮文字位置から最大で26文字前方に移動させながら繰り返します。図4の文字列例で言うと、圧縮文字位置にあるのは"A"で、Pindexの値が6(0始まりの7文字目)なので、処理は以下の流れで行われます。
比較文字位置は、Pindex から Distance を引いた数だけ前の文字になります。圧縮前の文字列 Plaindata の先頭添字は0なので、「Pindex-Distanceが0以上」であることを継続条件とすれば適切な動作となります。したがって[a]には「Pindex-Distance≧0」が入ります。
∴a=ア:Pindex-Distance≧0
〔bについて〕
空欄を含むIF文は、圧縮文字位置を先頭とする文字列と、比較文字位置を先頭とする文字列が何文字一致しているかを確認する処理です。真のときにループを抜け、偽のときに Fitnum(一致文字数を保持する変数)をインクリメントしています。ループを抜けるのは2つの文字が一致しないときです。
ここで、圧縮文字位置は Pindex、比較文字位置は Pindex-Distance、各文字列の先頭から何文字目の一致を確認しているかは Fitnum が保持しているので、比較する文字はそれぞれ Fitnum を使用して下記のように表せます。
例えば、図4の文字列の場合、圧縮文字位置(Pindex)から6文字前で文字が一致します。これは下記のように表せます(※Distance = 6)。
「ア」「ウ」はFitnum を使っておらず常に同じ文字と比較することになるので誤り、「ウ」はDistanceを加算しており比較する文字が圧縮文字位置より後ろになってしまうので誤りです。
∴b=エ:Plaindata[Pindex-Distance+Fitnum]
〔cについて〕
[a]を継続条件とするループ文は、前述のとおり、
∴c=イ:Distance ← Distance+1
〔dについて〕
この分岐処理では、Maxfitnum が-1(初期値)である場合と、そうでない場合に分けて処理を行っています。[d]を含むのは Maxfitnum が-1でない場合、すなわち前方に4文字以上の一致文字列が見つかったときの処理です。このときは、(5)④に説明されているように、対象部分を $xx という形式の圧縮列として Compresseddata[](圧縮後の文字列が格納される配列)に格納することになります。
圧縮列の格納と Compresseddata[] の文字位置を進める処理は[d]直前の4行の処理で済んでいるので、[d]には Plaindata[] の文字位置である Pindex を後ろに移動する処理が入ります。図4の例を確認すると、圧縮文字位置(7文字目)の6文字前から4文字が一致しているので、圧縮文字位置から数えて4文字目までが圧縮列に置き換えられることになります。このとき、次の圧縮文字位置として適切なのは、圧縮対象文字列の直後に位置する11文字目の"A"です。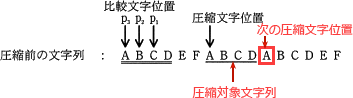 Pindex = 7、Maxfitnum = 4 のとき、次の圧縮文字位置が11となるので、次の Pindex は「Pindex+Maxfitnum」の式で求められることになります。よって、[d]には「Pindex をPindex+Maxfitnum」で更新する処理が入ります。
Pindex = 7、Maxfitnum = 4 のとき、次の圧縮文字位置が11となるので、次の Pindex は「Pindex+Maxfitnum」の式で求められることになります。よって、[d]には「Pindex をPindex+Maxfitnum」で更新する処理が入ります。
∴d=エ:Pindex ← Pindex+Maxfitnum
〔eについて〕
空欄部分は圧縮された文字列を、元の文字列に復元する処理です。
変数 Num が圧縮された文字数を、変数 Start が圧縮文字位置と比較文字位置の差を表現しています。それぞれ、副プログラム Compress でも同じような役割を持つ変数が存在します。
[b]と似た感じになりますが、圧縮文字位置(Pindex)から Fitcnt 番目の文字は、Start をオフセットとして下記のように表現できます。
「ア」「イ」は圧縮後の文字列を参照しているので誤り、「ウ」は Start を加算することにより Pindex より後方、つまり Plaindata の未格納領域を参照することになるので誤りです。
∴e=エ:Plaindata[Pindex-Start+Fitcnt]
空欄にはループの継続条件が入ります。このループ処理は、変数 Distance が26以下であることを1つの継続条件としていること、および直前処理で②の記述にあるように Distance の初期値を4にしていることから、問題文(4)③で説明されている
「比較文字位置を文字列の先頭に向かって,圧縮文字位置から最大26文字前まで移動させながら,次の(a),(b)を行う」
に該当することがわかります。
この処理では、「圧縮文字位置と比較文字位置から文字列の後方に向かって,圧縮文字並びと比較文字並びが何文字一致するかを調べる」ことを、圧縮文字位置から最大で26文字前方に移動させながら繰り返します。図4の文字列例で言うと、圧縮文字位置にあるのは"A"で、Pindexの値が6(0始まりの7文字目)なので、処理は以下の流れで行われます。
- Distance=4
- 比較文字位置は4文字前の"C"
"C"と"A"が不一致なので終了 - Distance=5
- 比較文字位置は5文字前の"B"
"B"と"A"が不一致なので終了 - Distance=6
- 比較文字位置は6文字前の"A"
"ABCD"までの4文字が一致するので、Fitnum=4で終了(図4の状態) - Distance=7
- 圧縮文字位置"A"の7文字前は存在せず、配列の範囲外(Plaindata[-1])を参照することになるのでループを抜ける
比較文字位置は、Pindex から Distance を引いた数だけ前の文字になります。圧縮前の文字列 Plaindata の先頭添字は0なので、「Pindex-Distanceが0以上」であることを継続条件とすれば適切な動作となります。したがって[a]には「Pindex-Distance≧0」が入ります。
∴a=ア:Pindex-Distance≧0
〔bについて〕
空欄を含むIF文は、圧縮文字位置を先頭とする文字列と、比較文字位置を先頭とする文字列が何文字一致しているかを確認する処理です。真のときにループを抜け、偽のときに Fitnum(一致文字数を保持する変数)をインクリメントしています。ループを抜けるのは2つの文字が一致しないときです。
ここで、圧縮文字位置は Pindex、比較文字位置は Pindex-Distance、各文字列の先頭から何文字目の一致を確認しているかは Fitnum が保持しているので、比較する文字はそれぞれ Fitnum を使用して下記のように表せます。
- Plaindata[Pindex + Fitnum]
- Plaindata[Pindex-Distance+Fitnum]
例えば、図4の文字列の場合、圧縮文字位置(Pindex)から6文字前で文字が一致します。これは下記のように表せます(※Distance = 6)。
Plaindata[Pindex] == Plaindata[Pindex - Distance]
また、圧縮文字位置から Discance だけ前の文字を先頭に4文字連続で一致している場合、下記のように表せます。Plaindata[Pindex + 0] == Plaindata[Pindex - Distance + 0]
Plaindata[Pindex + 1] == Plaindata[Pindex - Distance + 1]
Plaindata[Pindex + 2] == Plaindata[Pindex - Distance + 2]
Plaindata[Pindex + 3] == Plaindata[Pindex - Distance + 3]
Plaindata[Pindex + 4] != Plaindata[Pindex - Distance + 4]
Plaindata[Pindex + 1] == Plaindata[Pindex - Distance + 1]
Plaindata[Pindex + 2] == Plaindata[Pindex - Distance + 2]
Plaindata[Pindex + 3] == Plaindata[Pindex - Distance + 3]
Plaindata[Pindex + 4] != Plaindata[Pindex - Distance + 4]
「ア」「ウ」はFitnum を使っておらず常に同じ文字と比較することになるので誤り、「ウ」はDistanceを加算しており比較する文字が圧縮文字位置より後ろになってしまうので誤りです。
∴b=エ:Plaindata[Pindex-Distance+Fitnum]
〔cについて〕
[a]を継続条件とするループ文は、前述のとおり、
- Disntance が26以下であること
- Pindex-Distanceが0以上であること(DistanceがPindex以下であること)
∴c=イ:Distance ← Distance+1
〔dについて〕
この分岐処理では、Maxfitnum が-1(初期値)である場合と、そうでない場合に分けて処理を行っています。[d]を含むのは Maxfitnum が-1でない場合、すなわち前方に4文字以上の一致文字列が見つかったときの処理です。このときは、(5)④に説明されているように、対象部分を $xx という形式の圧縮列として Compresseddata[](圧縮後の文字列が格納される配列)に格納することになります。
圧縮列の格納と Compresseddata[] の文字位置を進める処理は[d]直前の4行の処理で済んでいるので、[d]には Plaindata[] の文字位置である Pindex を後ろに移動する処理が入ります。図4の例を確認すると、圧縮文字位置(7文字目)の6文字前から4文字が一致しているので、圧縮文字位置から数えて4文字目までが圧縮列に置き換えられることになります。このとき、次の圧縮文字位置として適切なのは、圧縮対象文字列の直後に位置する11文字目の"A"です。
∴d=エ:Pindex ← Pindex+Maxfitnum
〔eについて〕
空欄部分は圧縮された文字列を、元の文字列に復元する処理です。
変数 Num が圧縮された文字数を、変数 Start が圧縮文字位置と比較文字位置の差を表現しています。それぞれ、副プログラム Compress でも同じような役割を持つ変数が存在します。
- 変数 Num
- 副プログラム Compress の変数 Maxfitnum に対応する
- 変数 Start
- 副プログラム Compress の変数 Distance に対応する
[b]と似た感じになりますが、圧縮文字位置(Pindex)から Fitcnt 番目の文字は、Start をオフセットとして下記のように表現できます。
Plaindata[Pindex-Start+Fitcnt]
したがって「エ」が正解となります。「ア」「イ」は圧縮後の文字列を参照しているので誤り、「ウ」は Start を加算することにより Pindex より後方、つまり Plaindata の未格納領域を参照することになるので誤りです。
∴e=エ:Plaindata[Pindex-Start+Fitcnt]
設問2
次の記述中の に入れる正しい答えを,解答群の中から選べ。
次の文字列を圧縮した文字列を副プログラム Decompress を使って復元する場合,プログラム2のαの部分はf回実行される。
文字列 : ABCDEFGABCDEABCDFEFGABCD
次の文字列を圧縮した文字列を副プログラム Decompress を使って復元する場合,プログラム2のαの部分はf回実行される。
文字列 : ABCDEFGABCDEABCDFEFGABCD
f に関する解答群
- 3
- 4
- 5
- 6
- 7
- 8
解答選択欄
- f:
解答
- f=カ
解説
副プログラム Decompress のIF文の条件式は以下のようになっています。
圧縮前の文字列を先頭から走査し、圧縮列に置き換えていくと以下のように圧縮されます。なお、英字と数字は以下のように対応しています。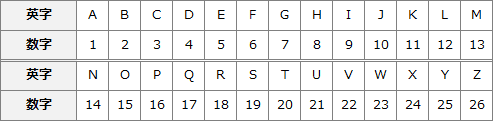
ABCDEFG$GE$EDF$MG
∴f=カ:8
Compresseddata[Cindex] != Esym
Esym には制御記号である"$"が格納されているので、このIF文は、圧縮文字列の現在文字が"$"ではないときに真となります。"$"ではない場合は圧縮列への置換が行われていないので、Compresseddata[Cindex] をそのまま Plaindata[Pindex] にコピーすることになります。α部分はこの処理を行っています。つまり、α部分の実行回数は圧縮後の文字列のうち、圧縮列以外の(置換対象とならなかった)文字の数と一致することになります。圧縮前の文字列を先頭から走査し、圧縮列に置き換えていくと以下のように圧縮されます。なお、英字と数字は以下のように対応しています。
- 8文字目の"A"から12文字目の"E"までが、先頭文字"A"の7文字前からの5文字に一致するので、"$GE"に置き換えられる。
ABCDEFGABCDEABCDFEFGABCD
↓
ABCDEFG$GEABCDFEFGABCD - 13文字目の"A"から16文字目の"D"までが、先頭文字"A"の5文字前からの4文字に一致するので、"$ED"に置き換えられる。
ABCDEFGABCDEABCDFEFGABCD
↓
ABCDEFG$GE$EDFEFGABCD - 18文字目の"E"から24文字目(末尾)の"D"までが、先頭文字"E"の13文字前からの7文字に一致するので、"$MG"に置き換えられる。
ABCDEFGABCDEABCDFEFGABCD
↓
ABCDEFG$GE$EDF$MG
ABCDEFG$GE$EDF$MG
∴f=カ:8